Большое будущее данных
.png "Большое будущее данных")
Все больше компаний осознают, что с данными пора что-то делать. Их то ли слишком много (девять десятых из того, что собирается, никак не используется), то ли слишком мало: из них невозможно понять, на что деньги тратятся впустую. По данным опроса, проведенного Высшей школой бизнеса НИУ ВШЭ в июле 2023 года, интеграция и визуализация данных — одно из самых активных направлений цифровой трансформации бизнеса. Более XX% компаний ведут работу по повышению отдачи от данных в 2023 году, а в ближайших планах она стоит у половины компаний. За исключением информационных брокеров, организации занимаются данными не ради самих данных: шансы принять правильное, максимально взвешенное решение увеличиваются, если вы располагаете качествен- ной и полной информацией и надежными показателями по многим аспектам своего бизнеса и конъюнктуры вокруг него.
С ростом компьютерных мощностей сбор данных из разных источников развивался лавинообразно, и в конце 1990-х появился термин «большие данные». В начале 2010-х предполагалось, что в сочетании с искусственным интеллектом большие данные обеспечат быстрый прорыв в аналитике.
Евангелисты Big Data объясняли, что если собрать данные воедино, то инструменты ИИ смогут извлечь из них полезные для компании инсайты, из которых легко будет делать выводы. Появилась профессия дата-сайентистов, на которых возлагали большие надежды. Затем наступил период некоторого отрезвления. Оказалось, что делать выводы из данных — с помощью ИИ или без него — дано далеко не каждой компании, а готовых решений нет. В 2023 году отмечен новый всплеск увлеченности большими данными: он связан с прогрессом в основных технологиях и общим увлечением «разговорным» искусственным интеллектом. Это не совсем та сфера, в которой предполагалось применять Data Science 10-15 лет назад, ведь тогда думали о наступлении ИИ широким фронтом во все ИТ.
Исследователи из DataBricks, ведущей компании мира по построению цифровых платформ, составили отчет на основе анализа потребностей своих клиентов. Они отмечают, что в последние полгода компании чаще всего адресуют в озеро данных запросы, связанные с подключением разго ворного ИИ. С его помощью они учатся извлекать, например, информацию о настроениях из отзывов потребителей о компании или продукте. Другие важные для бизнеса применения больших данных — симуляция и оптимизация, включая цифровых двойников, а также географическая и пространственная аналитика. Среди всех платформенных услуг Databricks наиболее быстрый рост наблюдается именно в решениях по интеграции данных: более чем вдвое за один год.
Все эти годы ведущие софтверные ком пании работали над решениями по управлению данными. Однако в силу сложности самого объекта, универсальных систем в интеграции и анализе данных до сих пор нет, и вряд ли они появятся в ближайшей перспективе. Имплементация решения в этой сфере потребует немалых усилий от компании-покупателя.
Российские компании много лет пользо вались интегральными решениями мировых лидеров: SAP, Oracle, Microsoft, IBM, Informatica. Курс на импортозамещение и уход из России западных поставщиков не мог не сказаться на организациях, которые успели адаптировать их продукты. Может показаться, что они зря потратили силы и средства на системы, которые впоследствии оказались недоступными, но с другой стороны, опыт внедрения передовых западных решений помог им накопить собственные компетенции в сфере данных. Таким компаниям легче сделать осознанный выбор ПО в нынешних условиях.
«Главное — не паниковать и не спешить отказываться от достижения цели. Важно оста ваться гибкими, и эту гибкость закладывать в планы развития», — так описал свой подход Егор Донцов, архитектор данных компании «Сибур Диджитал». На конференции по качеству данных в Москве в марте 2023 года он рассказал, как действовал Сибур после того, как стали недоступны инструменты SAS по качеству данных, ранее внедренные в «Сибур Диджитал». Потерпев неудачу с поиском замены, то есть обнаружив, что на российском рынке нет подходящих коммерческих решений, решили ориентироваться на продукты open source. Систему начали строить на основе языка Python и библиотеки Great Expectations. Проект был запущен в декабре, а готовый продукт планируется получить к концу второго квартала 2023 года, объявил Егор Донцов.
В России управление данными остается одним из ключевых трендов цифровой трансформации. По оценке Ассоциации больших данных, использование больших данных в разных отраслях принесет экономике дополнительные 1,6 трлн. рублей операционной прибыли. 45% крупных компаний планируют в первую очередь импортозамещать именно решения по управлению данными (результаты исследования DIS Group, сентябрь 2022 года).
Данными приходится делиться
До недавних пор в бизнесе не было принято обоществлять данные. Вследствие жесткой иерархичности оргструктур каждое функциональное и региональное подразде ление существует в своей «башне», собирает свои данные, хранит их в форматах, удобных именно этому подразделению. Исследователи много пишут о том, что в традиционных компаниях информация собрана хаотично и хранится разрозненно. Очень часто данные, необходимые для того, чтобы достоверно вывести ключевые показатели, вообще отсутствуют. «Владельцы продукта или процесса, по которому собирают данные, должны понимать, что данные — это ключевой актив, и обеспечивать полноту и качество потока. Только при этом условии возврат на инвестиции в данные будет расти».
Сейчас, когда многие поверили в то, что «данные — это новая нефть», инвестиции бизнеса в них растут год от года во всем мире. Однако наладить их сбор, хранение, контроль качества, и интеграцию — очень непростая задача для любой организации, включая «цифровых аборигенов».
New Vantage Partners, исследовательская и консалтинговая фирма в сфере данных и ИИ для компаний списка Fortune 1000, ежегодно проводит опросы топ-менеджеров. Основатель этой фирмы Рэнди Бин в 2023 году в статье, посвященной итогам последнего опроса, отметил, что хотя инвестиции в данные являются одним из приоритетов для крупнейших компаний, лишь 23,9% респондентов считают, что достигли целей преобразования бизнеса на основе данных (четыре года назад таких был 31%). Более того, в 2022 году лишь 20,6% респондентов сообщили, что в их организациях утвердилась соответствующая «культура», то есть массовое желание и умение работать с данными (в 2019 году таковых было 28,3%). В другой статье в HBR Рэнди Бин признает, что «усилия бизнеса по включению потоков данных в процессы принятия решений были не столь успешными, как лидеры компаний предполагали ранее». Означает ли это, что все годы, прошедшие после прихода «боль ших данных» в бизнес, компании топчутся на месте? В чем главное препятствие, ведь нет недостатка в коммерческих решениях, позволяющих интегрировать операционные данные и обогащать их данными из внешних источников? По данным упомянутого опроса топ-менеджеров, главная причина медленного прогресса в этой сфере — корпоративная культура.
Речь идет, с одной стороны, о нежелании правильно собирать и хранить данные и де- литься ими с другими, а с другой — о желании принимать решения самостоятельно, исходя из своего опыта и интуиции, основываясь на собственных данных. Но интуиция обманчива, а собственные данные редко бывают полными и индикативными. Ловушки человеческого мышления более 20 лет назад разоблачил Даниэль Канеман, получивший Нобелевскую премию по экономике. В книге «Думай медленно, решай быстро» он разбирает психологическую подоплеку ошибок, которые человек совершает, полагаясь на опыт и интуицию. Позднее он и его соавторы опубликовали в HBR статью, объясняющую, почему простые алгоритмы зачастую справляются с управленческими решениями лучше, чем человек.
В компаниях нежелание передавать куда-то данные объясняют еще и рисками утечек информации. Мы постоянно слышим о том, что ту или иную базу данных «слили». По данным американской НКО ITRC, собирающей информацию об утечках персональных данных, за первую половину 2023 года данные о 150 млн американцев были так или иначе скомпрометированы. Причиной утечек, как правило, становились кибератаки (1000+ эпизодов) и лишь в гораздо меньшей мере ошибки сотрудников или системных администраторов. Интеграция данных сама по себе не увеличивает риск утечек, ведь используемые в ходе процесса решения более современны, нежели те, что были заложены в архитектуру ИТ компании в ходе ее истории. Средства интеграции предполагают шифровку, токенизацию или маскирование данных, а старые системы хранения и управления базами данных, гораздо более уязвимы.
Задачи руководителей компаний, таким образом, лежат не только в плоскости имплементации новых технологий работы с данными, но и в способности организации собирать, надежно хранить и организовывать ее собственные данные.
Очистка, обогащение и интеграция данных
Современные инструменты интеграции данных совсем не похожи на те, что использовались 20 лет назад. Теперь не нужно переносить колонки из одной таблицы Excel в другую: множество массивов можно объединить автоматически, поместив их в программную среду, которая заодно обеспечит их очистку. Пользователям таких систем не обязательно быть инженерами-программистами или даже аналитиками данных: продвинутые решения позволяют сливать датасеты средствами low-code или no-code. Процесс интеграции подразумевает, во-первых, выгрузку данных из разрозненных источников и их очистку от мусора (extraction and cleansing), включая удаление заведомо ошибочных, недостоверных и дублирующих записей. Во-вторых, записи конвертируются в нужный формат, претерпевая изменения, такие как анонимизация и присвоение метаданных (transformation). И в-третьих, их загружают (loading) в среду, которая позволит работать с полученным датасетом, автоматически извлекая из него статистические или иные инсайты — обычно после расширения или дополнения исходного датасета. Эти три составные части интеграции данных сокращенно называют ETL. В последнее время, в связи с массовой миграцией в облако систем для хранения данных, порядок действий часто бывает иным: извлечение, загрузка и в последнюю очередь трансформация, то есть ELT.
Исходные данные дополняют информацией из внутренних и внешних источников: как коммерческих, так и общедоступных. Цель — сделать датасет более полным и полезным для анализа, принятия решений или использования другими информационными системами.
Источники для обогащения датасета разнообразны. Ниже приведен их неполный список.
- Географические данные, маркетинго вые исследования, экономические показатели. Например, Всемирный Банк для получения более детальной картины нищеты в отдаленных районах Мексики использовал не только сведения из опросов и переписи населения, но и данные аэрофотосъемки. С помощью инструмента Earth Engine компании Google можно довольно точно установить реальный уровень благосостояния деревни или даже домохозяйства.
- Геокодирование: присвоение географических координат точкам данных на основе их адресов и информации о местоположении. Геокод дает пространственную информацию и обеспечивает дополнительную визуализацию, например, для ритейла, который выбирает новые точки для своих магазинов среди доступных адресов.
- Коммерческие базы данных. Поставщики таких баз (информационные брокеры) торгуют большим набором сведений о физлицах: демографическая информация, личные предпочтения, покупательское поведение и прочее. Еще более широкий спектр сведений доступен о юридических лицах. В США коммерческие базы данных — многомиллиардный бизнес. Подписка на такие сервисы, как Dun & Bradstreet (полный реестр и детальные сведения о компаниях США), Proquest (данные о научных исследованиях и разработках), Lexis Nexis (правовая информация) и множество баз данных о людях как потенциальных потребителях — условие существования любой крупной компании. Облако Dun & Bradstreet Data может быть интегрировано с данными компании, которая пользуется такими ERP-системами, как Exact, Salesforce, SAP, Oracle, Microsoft, Onguard and CreditTools. В России базы данных о компаниях, а также, например, справочники по номенклатуре изделий тоже интегрируют с операционными данными и географическими ресурсами.
- Результаты лингвистического анализа (NLP). Появились программы, которые в потоке письменной или устной речи могут выделить ключевые слова, по которым они определяют не только темы сообщений, но и о общее настроение высказывания. Это приносит пользу не только маркетологам, но и службам безопасности.
- Мониторинг социальных сетей. Компании мониторят соцсети, чтобы получить информацию, связанную с интересующими их брендами или общественным мнением по важным вопросам. Мониторинг позволяет анализировать настроения, а также извлекать контент, созданный пользователями.
- Агрегация данных. Сбор данных по всем точкам контакта с клиентом дает более полное представление о его поведении и предпочтениях. Этим пользуются, например, банки, чтобы персонализировать свое предложение. А у компаний бигтеха, таких как Google и Amazon, агрегация данных о пользователе — основной механизм коммерциализации: на этом зиждется показ рекламы, рекомендации, платные сервисы и пр. Объединение потоков данных и их подпитка из других источников может происходить однократно — когда вы слива ете статичные датасеты один раз, а может осуществляться периодически, в пакетном режиме по мере их накопления. Сейчас все больше распространяются инструменты, объединяющие данные из разных источников в режиме реального времени. Это особенно важно для анализа данных с разных датчиков (в интернете вещей) и для пользовательских платформ.
Цифровая зрелость и стратегия интеграции данных
Томас Чаморро-Премузик пишет в HBR, что неудачными оказываются девять из десяти цифровых трансформаций. Большинство глобальных консалтинговых фирм сходятся во мнении, что сколь бы прекрасной ни была новая технология, попытки бизнеса овладеть ею чаще всего обречены с самого начала. Международные консалтинговые компании «большой четверки» — McKinsey, BCG, KPMG и Bain & Company — оценивают долю неудачных цифровых преобразований в диапазоне от 70% до 95%.
Ведущая фирма по ИТ-консалтингу Freeform Dynamics вместе с японской Fujitsu провели исследование зрелости систем работы с данными по 400 компаниям разных отраслей из 14 стран Западной Европы. В результате было выделено четыре этапа развития таких систем, и выявлена серьезная корреляция между уровнем зрелости работы с данными и финансовыми результатами компании.
Для раннего этапа — уровня «цифровой бедняк» характерен хаотичный подход к сбору и хранению данных, следствием чего является их низкая видимость при высоких рисках. Примерно 5% компаний выборки пребывали на этом уровне в конце 2020 года.
Компании уровня «цифровой владелец» обладают базовыми компетенциями в сфере обращения с данными, однако видимость носит фрагментарный характер, причем система способна «высвечивать» прошлое гораздо лучше, чем настоящее или будущее.
На уровне «цифровой управленец» нуж ная информация и инсайты сравнительно легко извлекаются из данных, которые полны и непротиворечивы; можно делать прогностические выводы.
Наконец, на уровне «цифровой повелитель» картина обновляется в режиме реального времени, инсайты появляются постоянно и все функции выигрывают от проактивной аналитики происходящего.
К последнему уровню исследователи отнесли лишь 4,8% выборки. По результатам анкетирования более 90% компаний находятся на втором или третьем этапе развития.
Генеральный директор Microsoft Сатья Наделла и профессор Гарвардской школы бизнеса Марко Янсити выделили несколько необходимых компонентов масштабных преобразований.
Навыки. Умение работать с разнообразными данными в цифровой среде должно распространиться далеко за пределы ИТ-функции. Организация инвестирует в обучение сотрудников, внедряет подходы agile и повсеместное экспериментирование.
Технологии. Важно правильно подобрать инструменты, особенно в сфере ИИ. Платформы должны быть настолько простыми, чтобы ими могли пользоваться специалисты любого профиля, участвующие в инновационной деятельности.
Архитектура. Соединение человеческого и технологического потенциала требует особой архитектуры - как в сфере ИТ, так и в организации в целом. Чтобы собрать воедино и сделать доступными для распределенной рабочей силы массивы данных, эта архитектура должна поддерживать совместное использование, интеграцию и нормализацию данных.
Эти три условия вместе повышают цифровую интенсивность бизнеса. Авторы статьи объяснили, как можно измерять цифровую интенсивность по аналогии с экономической интенсивностью, показывающей степень задействования актива. Оценив цифровую интенсивность 150 фирм, Наделла и Янсити обнаружили, что у верхнего квартиля выборки темпы роста дохода более чем вдвое превосходят темпы роста нижнего квартиля.
Для успеха цифровизации бизнеса необходимы подготовленность организации и стратегическое видение ее руководителей. Решения в сфере данных стоят недешево, и по результатам глобального опроса BCGI8 топ-менеджеры остаются ими недовольны по нескольким причинам. Во-первых, это неудобная координация и недостаточная поддержка со стороны поставщиков - ее отметили 84% опрошенных. На втором месте (74%) отмечают шаблонные, недостаточно кастомизированные решения. На третьем месте (69%) - некачественное обучение сотрудников компании.
О том, какие шаги необходимо сделать для выработки стратегии данных, см. врез «Стратегия интеграции данных». Примером удачного выстраивания стратегии данных может служить Tesla, которая сумела вывести из них важный показатель. В нескольких штатах США компания предлагает страхование автомобилистов на основе автоматически выводимого интегрального показателя «общей безопасности». С датчиков автомобиля Tesla снимает физическую информацию: скорость, время в пути, маршруты поездок, состояние водителя и пр. Множество показателей сводится в один скоринг, который вычисляется ежемесячно. Средний по скорингу водитель может рассчитывать на 20-40% скидки по страховке, а самый аккуратный - на 40-60%, утверждает Tesla.

Как обеспечивается интеграция?
Крупные компании, в особенности технологические, разрабатывают инструменты интеграции самостоятельно и хранят их либо на собственном сервере, либо в собственном облаке. Например, «графы данных», как у Amazon или Google, построены на постоянно обновляющихся данных о том, как пользователь ведет себя на их сайтах: куда заходит, чем интересуется, насколько долго выбирает. Данные интегрируются по каждому пользователю, и на их основе создается персонализированное предложение.
Создание и поддержание собственных инструментов интеграции и интеллектуального анализа данных может оказаться очень затратным и требует мощных ИТ-ресурсов. Поэтому большинство компаний подписывается на проприетарные решения по модели SaaS (Software as a Service). Гэри
Хагмюллер, глава Arcion, поставщика решений для интеграции баз данных в режиме no-code, говорит: «Научиться надежно собирать качественные данные критически важно для любой системы ИИ, которую вы собираетесь встроить в свою операционную деятельность. Данные и их форматы меняются, устаревают и «портятся» по мере движения от места создания до места использования. Поэтому в инструмент ИИ, который вообще очень чувствителен к данным и их качеству, следует заложить способность к самоисцелению». Современные решения для интеграции данных справляются с изменениями благодаря способности улавливать изменения данных в реальном времени и распознавать изменения в форматах данных или в самих данных на лету (change data capture (CDC)). А вице-президент Microsoft по маркетингу цифровых и ИИ-решений Джессика Хок обещает клиентам извлечь максимум из данных, потому что Azure Data Factory обладает следующими свойствами: «Упрощенная миграция данных в систему, извлечение, трансформация, загрузка средствами low-code и no-code, операционные данные в потоке, управление метаданными и контроль данных».
Многие существующие на рынке решения представляют собой комплексы: с одной стороны, это средства очистки, контроля и объединения баз данных, а с другой - набор полезных для бизнеса внешних датасетов, которые поддерживает вендор внутри своего облака или за его пределами. Например, компания Oracle недавно сообщила, что сотрудничает с 80 информационными брокерами, обеспечивающими сбор и хранение самой разнообразной информации о людях, бизнесах, ресурсах и рынках.
Следует помнить, однако, что использование сторонних датасетов о людях регулируется законами: Евросоюз еще в 2018 году принял единый регламент General Data Protection Reglament (GDPR), обязательный для всех стран. Он ограничивает как сбор, так и использование персональных данных.
В США защита персональных данных пока не такая строгая, но резиденты некоторых штатов, например Калифорнии, могут потребовать удаления всех записей о себе в любой организации. Тем не менее брокеры продолжают собирать данные о миллионах и миллиардах людей. Журнал Wired назвал угрозой демократии само существование таких брокеров, как Acxio, CoreLogic и Epsilon. «CoreLogic собрала информацию по всем владельцам недвижимости США и торгует этими данными. В базе данных Асхіот сведения о 2,5 млрд физлиц, это не просто демографические и паспортные характеристики, но и такие сведения, как автокредиты, поездки, финансовая надеж-ность и стабильность - всего более 11 тыс. атрибутов, то есть полный профиль», - негодуют авторы статьи.
Интеграция данных в бизнес-экосистемах - отдельная задача со своими рисками и способом создания стоимости. Участники экосистем делают данные доступными для ее организатора и отчасти для других участников, получая взамен рыночную выгоду.
Современные тренды интеграции данных
Большинство исследователей подчерки-вают, что все чаще для очистки, обогащения и интеграции данных компании используют облачные сервисы. Вот некоторые тренды, замеченные исследователями, в том числе компанией Gartner.
• Интеграция данных в реальном времени. С ней мы сталкиваемся всякий раз, когда государственный или частный сервис, например сайт банка, предлагает авторизоваться через «Госуслуги» или когда мы платим на сайте банковской картой. Интеграция платежной системы и компании-продавца происходит моментально, то есть изменения, зафиксированные банком (списывание денег со счета), тут же отражаются в базе данных продавца, которая отправляет вам уведомление об этом через свой клиентский интерфейс. Интеграция в реальном времени полезна в тех отраслях, где сделки носят высокочастотный характер, и там, где задействован интернет вещей.
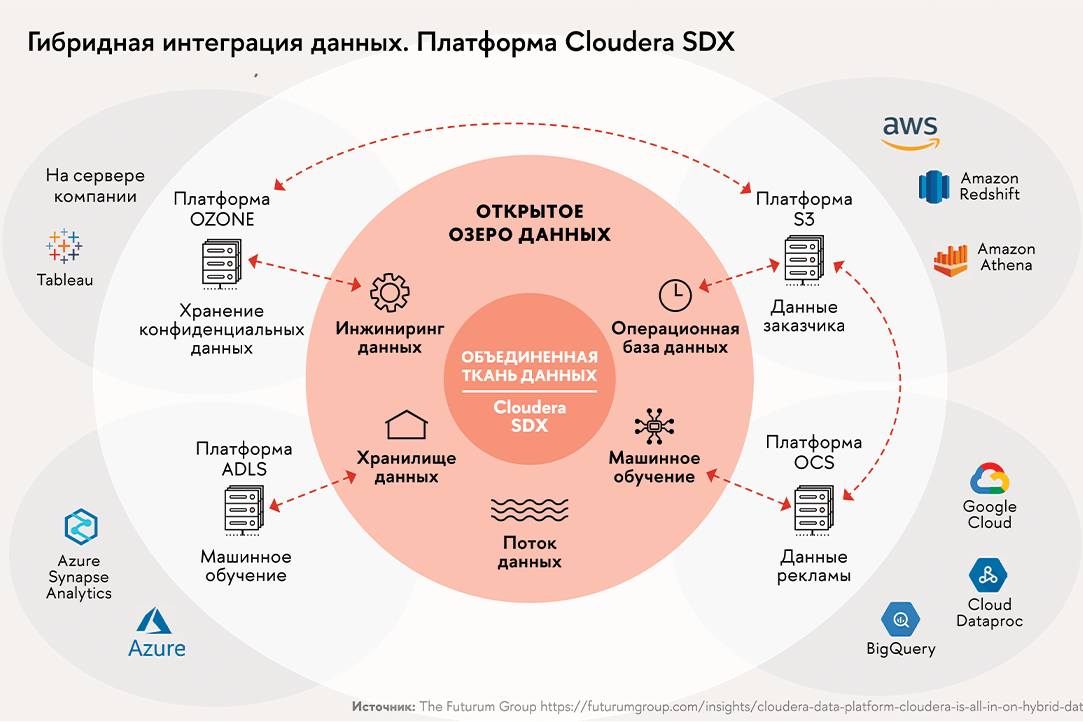
• Гибридная интеграция данных. Этот подход вытекает из потребности децентрализовать управление данными (см. врез выше). Например, в экосистемах, где каждый участник остается хозяином своих данных и хранит их у себя. Но и внутри одной компании, особенно если она крупная и мультинациональная, причем операционные данные хранятся на разных серверах и в облаках, гибридная интеграция может оказаться более выгодным решением, нежели миграция всех датасетов в одно облако. Благодаря гибридной модели с вертикальной и горизонтальной интеграцией аналитические инструменты, такие как машинное обучение, могут обращаться к массивам, физически расположенным на разных облачных платформах.
С приходом интернета вещей гибридные платформы стали все шире использоваться как производителями устройств, так и об-служивающими организациями. А объединив общедоступные данные метеосводок, данные геолокации и потребления электроэнергии, энергетики предсказывают скачок спроса и предотвращают отключения.
• Использование ИИ и машинного обучения. Успехи разговорного ИИ вроде
ChatGPT могут создать впечатление, что извлечение информации из текста, поиск значимых сущностей и их отождествление по разным источникам - пройденный этап в развитии интеллектуальных систем.
На самом деле это совсем другая задача, к которой генеративный ИИ имеет лишь косвенное отношение. Каждая задача по извлечению информации из крупных массивов текстовых данных уникальна, и результаты работы таких систем требуют экспертной коррекции. К тому же, как мы уже отмечали, системы ИИ очень чувствительны как к качеству входного потока, так и к изменениям в самих данных либо их формате. ИИ призван находить закономерности в массивах на основе статистического моделирования. Пока же главными преимуществами его использования в процессах ETL являются существенное сокращение затрат на трансформацию данных, упрощение картирования и классификации данных с разнесением по датасетам.
Сравнение решений для интеграции данных
Исследовательская компания Gartner eжегодно ранжирует коммерческие программные решения для большинства классов бизнес-задач. По каждому из видов софта составляется рейтинг, который для наглядности помещают в диаграмму, называемую «Волшебным квадратом». Попадание в этот «квадрат» становится предметом гордости компаний. Gartner исходит не только из нынешнего уровня развития той или иной софтверной системы, но и из того, насколько вектор ее развития совпадает с прогнозами Gartner на ближайшие годы.
Вот что должно произойти в интеграции данных, по мнению аналитиков Gartner.
- На протяжении 2024 года примерно вдвое сократится потребность в ручном выполнении задач по интеграции данных. Это станет возможным благодаря более массовому применению технологии «ткань данных», которая поддерживает интеграцию расширенных данных.
- К 2024 году управление и интеграция расширенных данных на основе ИИ снизят потребность в ИТ-специалистах на 30%.
- К 2025 году инструменты интеграции данных, не способные обеспечить клиентам работу с данными, расположенными в разных облаках по модели PaaS (плат-форма как сервис), уступят половину своей доли рынка тем вендорам, которые на это способны.
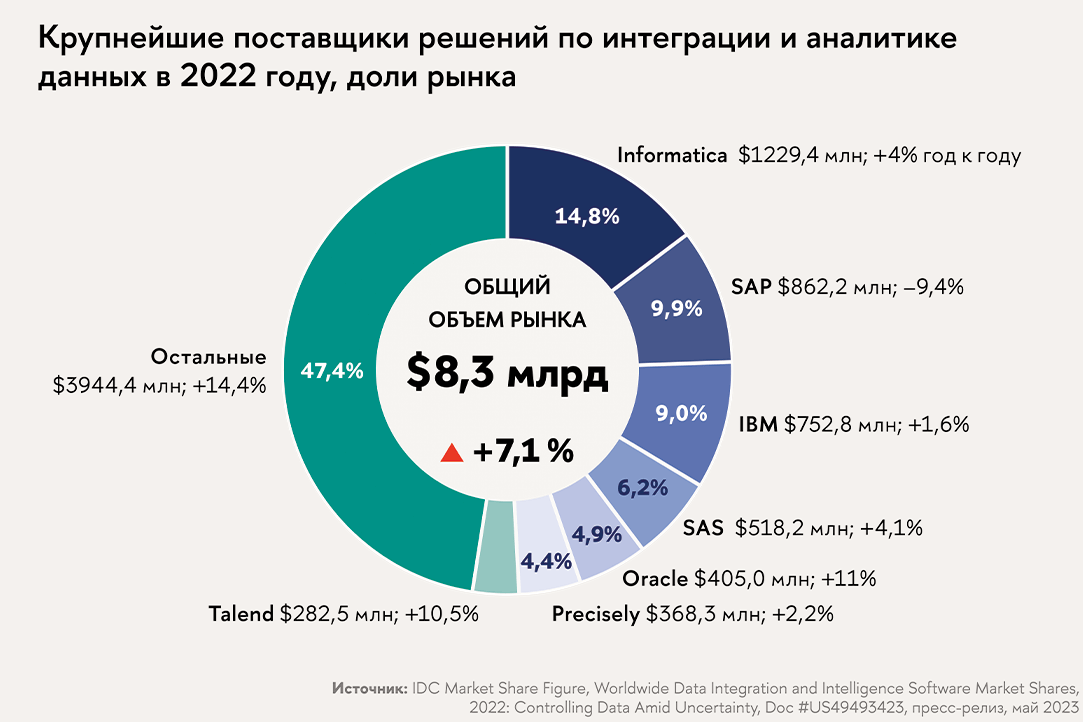
В рейтинге самых передовых решений Gartner в число лидеров попали Informatica, Oracle, IBM, Talend, SAP, Microsoft, Denodo, причем Informatica опережает всех своих конкурентов по премьер-лиге. Согласно докладу IDC, та ж Informatica стала чемпионом и по доле рынка (см. врез слева). Другие вендоры, отмеченные Gartner как передовые, обеспечили себе по несколько процентов мирового рынка. Однако почти половина общего объема приходится на поставщиков с долями менее 3%, причем доля «мелких» вендоров за год выросла на 14 процентных пунктов. Высокая фрагментация рынка говорит об остроте конкуренции. По мнению аналитиков Market Research Future, к 2030 году мировой рынок систем управления данными превысит $1,5 трлн.
Universe Data - российский разработчик решений по управлению данными (в прошлом компания входила в рейтинг Gartner). В январе 2023 года Universe Data запустила собственную платформу данных. По мнению ее гендиректора Владислава Каменского, решения на этой платформе смогут заменить SAP, SAS, Oracle, Informatica и IBM в части управления справочными и операционными данными.
Однако, по мнению опрошенных CNews экспертов, зрелость российских решений пока несопоставима с западными. «Тут все просто: количество клиентов совершенно разное. Там тысячи, даже десятки тысяч, а здесь единицы и в лучшем случае десятки», - говорит Юлий Гольдберг, руководитель направления импортозамещения GlowByte. Он призывает оценивать не абсолютную, а относительную зрелость, то есть возможность внедрения у крупных и привередливых заказчиков
Судя по числу внедрений, таких продуктов уже достаточно. Некоторые модули, такие как BI (бизнес-аналитика) или RPA (робото-промышленная автоматизация), уже «более-менее созрели», а, скажем, решения в сфере мастер-данных или Data Governance «пока в процессе», полагает Юлий Гольдберг.
Главным двигателем интеграции, скорее всего, будут данные о людях - хотим мы этого или нет. Следует также ожидать роста рынка для данных с умных устройств. Компании будут и дальше объединять данные в экосистемы. Например, Cosmose AI, собрав анонимизированные данные со смартфонов примерно 1 млрд человек, отслеживает траектории движения посетителей магазинов и объединяет их с данными датчиков внутри магазинов, что позволяет лучше понять, как эффективнее использовать площади. А недавно Cosmose AI взяла в партнеры компанию блокчейна Near, чтобы посетители подключенных магазинов (от Gucci до Walmart) могли расплачиваться криптовалютой.
Футуристы сходятся во мнении, что рано или поздно произойдет слияние самых лучших систем аналитики данных с применением ИИ и технологий блокчейна, обеспечивающих наилучшее качество самих данных. По одним оценкам, это произойдет уже через год, а по другим - через 15 лет.
Полные версии вы можете приобрести в Издательском доме НИУ ВШЭ